3R in der präklinischen Forschung
3. Erste Schritte in der Datenvernetzung sind gemacht
Industrie leistet Pionierarbeit zur Verringerung von Tierversuchen
In einem viel beachteten Projekt haben sich vier pharmazeutische Unternehmen mit Unterstützung der Europäischen Vereinigung der Pharmazeutischen Industrie und ihrer Verbände (EFPIA) zusammengetan, um in Kooperation mit der Europäischen Chemikalienagentur (ECHA) eine freiwillige, nicht gewinnorientierte Initiative zur Bereitstellung von Daten durch die Industrie zu starten. Ziel ist es, hochwertige, bisher unveröffentlichte physikalisch-chemische, toxikologische und ökotoxikologische Stoffdaten aus den Archiven der Unternehmen öffentlich zugänglich zu machen. Dank dem erweiterten Zugang zu Gefahrendaten zu Chemikalien wird die Effektivität datenbankgestützter Instrumente zur Vorhersage von Eigenschaften von chemischen Stoffen verbessert. Die Daten können darüber hinaus von Experten aus der akademischen Wissenschaft oder aus den Unternehmen der forschenden pharmazeutischen Industrie für Modelle genutzt werden, um Tierversuche für chemische Stoffe schrittweise zu reduzieren oder ganz zu vermeiden. Die ECHA hat sich bereit erklärt, diese Initiative zu unterstützen und als Makler und neutrale Plattform für die Verbreitung dieser Daten zur Verfügung zu stehen. Zurzeit läuft eine Testphase, an der die ECHA, die EFPIA und die Unternehmen Boehringer Ingelheim, F. Hoffmann-La Roche, Johnson & Johnson und Merck KGaA beteiligt sind. Ziel ist es, ein Programm zu schaffen, an welchem sich weitere Unternehmen beteiligen und ihre Archivdaten zur Verfügung stellen.
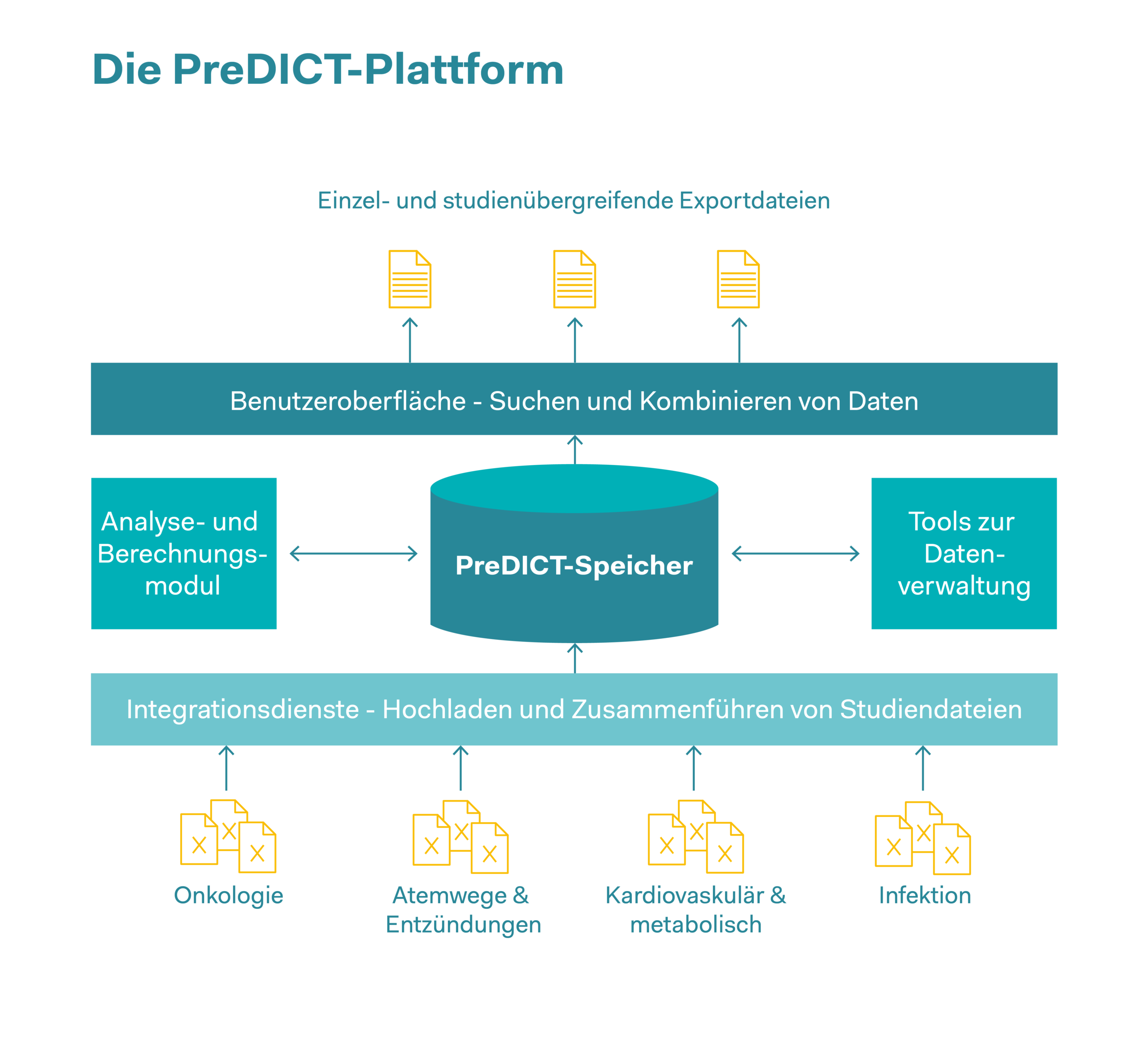
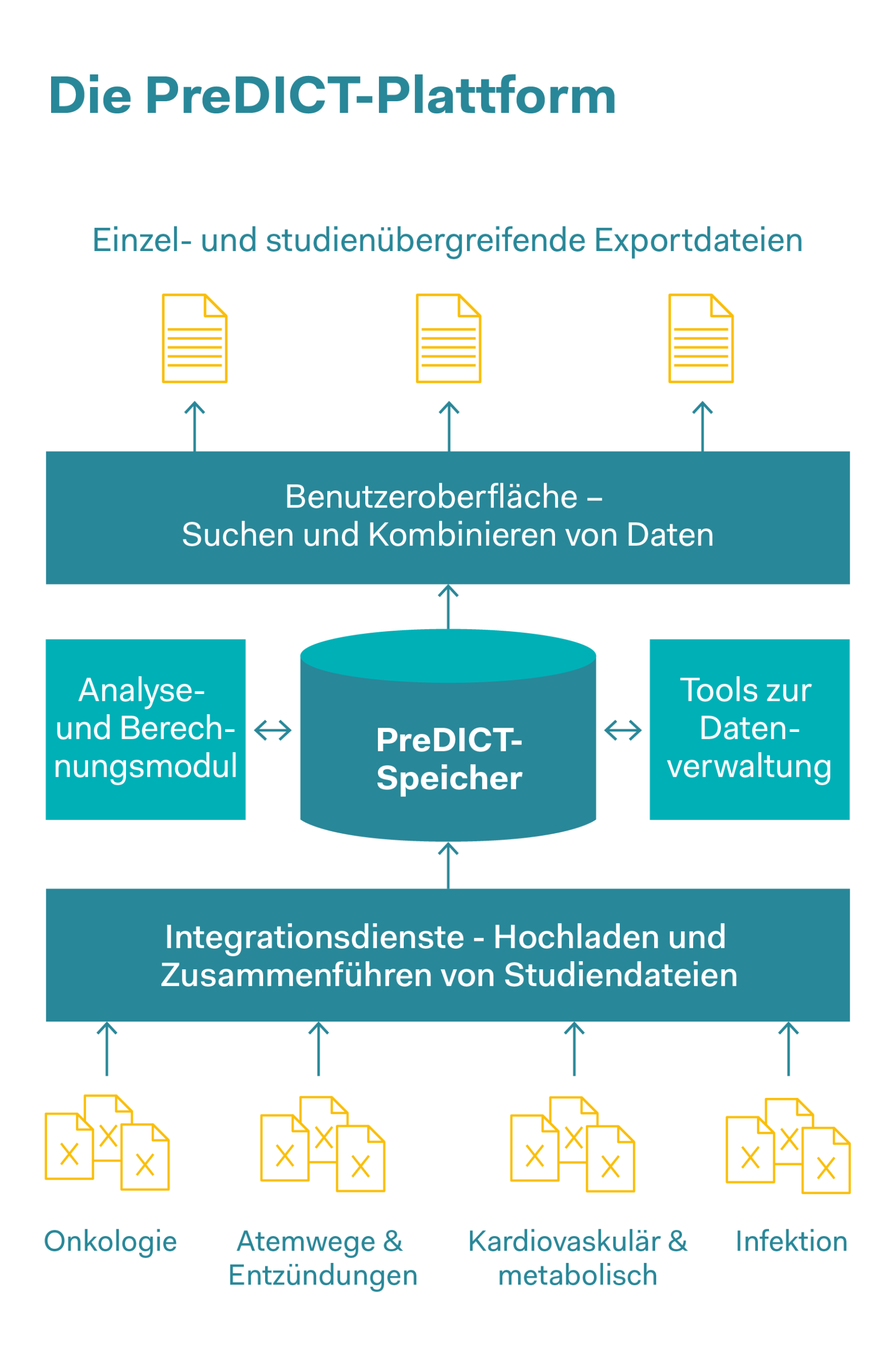
Mit Datenplattformen die 3R voranbringen Heute erfolgt die Erfassung, Speicherung und gemeinsame Nutzung komplexer Datensätze in Pharmaunternehmen oft auf der Grundlage von Tabellenkalkulationen. Die Plattform PreDICT (Preclinical Data Integration and Capture Tool) von AstraZeneca wurde in Zusammenarbeit mit dem Datenanalyseunternehmen Tessella entwickelt. Dabei wurde zunächst eine Reihe von Datenstandards definiert, mit denen sich In-vivo-Studiendaten aus allen Forschungsbereichen klar und vollständig darstellen lassen. Erfasst und analysiert wurden präklinische pharmakokinetische Daten (diese Daten beschreiben die Gesamtheit aller Prozesse, denen ein Arzneistoff im Körper unterliegt, wie die Aufnahme des Arzneistoffes, die Verteilung im Körper sowie der biochemische Um- und Abbau), pharmakodynamische Daten (Daten zu unerwünschten Wirkungen und zur richtigen Dosierung, um die erwünschte Wirkung im Körper zu erzielen) sowie Wirksamkeitsdaten. Das System gewährleistet Datenintegrität und ermöglicht Wissenschaftlern, In-vivo-Datensätze für die Vorhersage optimaler Dosierungen und Zeitpläne in klinischen Studien schnell zu finden, zu integrieren und gemeinsam zu nutzen. Nebst Zeitersparnissen, einer Reduzierung von Outsourcing-Kosten und vereinfachten Arbeitsabläufen konnten auch eine signifikante Verbesserung der Datenqualität und ein erhöhtes Vertrauen in die Daten festgestellt werden. Der schnelle Zugriff zu qualitativ hochwertigen Daten macht es für Forschende wesentlich einfacher, Modelle für das Verhalten von Arzneimitteln in realen Organismen zu entwickeln. Die Vorhersagen dieser Modelle sollen zudem In-vivo-Experimente teilweise gänzlich ersetzen oder dazu genutzt werden, um pro eingesetztes Tier ein Maximum an Erkenntnissen zu gewinnen sowie die Zahl der eingesetzten Tiere zu verringern.
Reduce
Die Möglichkeit, auf einen grossen Datenbestand zurückzugreifen, hilft Forschenden, das Design von Experimenten so zu optimieren, dass für jedes verwendete Tier ein Maximum an Erkenntnissen gewonnen wird. Der Zugriff auf Archivdaten fördert, bereits durchgeführte In-vivo-Versuche zu vermeiden und die Zahl der in neuen Studien verwendeten Tiere zu verringern, beispielsweise durch die Wiederverwendung von Kontrollgruppendaten aus vergleichbaren früheren Studien.
Replace
Der schnelle Zugang zu qualitativ hochwertigen Daten erleichtert Forschenden, Modelle für das Verhalten von Wirkstoffen in realen Organismen zu entwickeln. Je besser die In-vivo-Daten gepflegt werden, desto wahrscheinlicher werden zuverlässige Modellvorhersagen, welche In-vivo-Versuche ersetzen könnten.
Refine
Die Datenbank ermöglicht, Datensätze aus vielen Studien in einer Meta-Analyse zusammenzuführen, und liefert einen umfassenden Einblick in die Art und Weise, wie die Tiere verwendet wurden. Das unterstützt die Verfeinerung von In-vivo-Versuchen.
Mit Big Data zu besserer Forschung und mehr Patientensicherheit
Unterstützt von verschiedenen pharmazeutischen Unternehmen und Partnern aus der Akademie, hat das Technologieunternehmen GMV im Rahmen von eTRANSAFE eine biomedizinische Datentechplattform geschaffen, die die Entwicklung neuer Medikamente verbessern und für Patientinnen und Patienten sicherer machen soll. Das übergreifende Ziel von eTRANSAFE war es, die Vorhersagbarkeit, Durchführbarkeit und Zuverlässigkeit der Sicherheitsbewertung während des Entwicklungsprozesses von Medikamenten drastisch zu verbessern. Dies wurde durch die Entwicklung der eTRANSAFE-ToxHub-Plattform erreicht, die präklinische und klinische Datenbanken in einer integrativen Dateninfrastruktur zusammenführt und mit innovativen Berechnungs- und Visualisierungswerkzeugen kombiniert. Damit wurde eine ausreichende Menge an biomedizinischen Daten generiert, um mittels Big Data-Technologien Schlussfolgerungen zu ziehen. Der Nutzen des Projekts liegt in effizienteren Studien, kürzeren Forschungszeiten und besseren Toxizitätsergebnissen. Ein Teil des Projekts vergleicht präklinische mit klinischen Studien, um besser vorhersagen zu können, was in der klinischen Phase beim Menschen passiert.
«eTRANSAFE» – ein Projekt der «Innovative Medicines Initiative»
eTRANSAFE wurde entwickelt im Rahmen der «Innovative Medicines Initiative (IMI)», Europas grösster öffentlich-privater Initiative, die unter anderem vom Forschungs- und Innovationsprogramm Horizon 2020 der Europäischen Union und von der Europäischen Vereinigung der Pharmazeutischen Industrie und ihrer Verbände (EFPIA) unterstützt wird. Das Projekt wollte, unter Einhaltung von Data-Governance-Techniken, eine Vielzahl an präklinischen und klinischen Daten verfügbar machen. Eine Voraussetzung dafür war die Verfügbarkeit relevanter, qualitativ hochwertiger Datensätze. Um diese Daten optimal nutzen zu können, mussten jedoch wichtige Herausforderungen bewältigt werden, wie die Förderung des Informationsaustauschs zwischen konkurrierenden Organisationen oder die Förderung einer angemessenen Kontrolle, Standardisierung und Kommentierung der Datenqualität.