Les 3R dans la recherche préclinique
2. Rendre exploitable le potentiel des mégadonnées et de l’intelligence artificielle pour les 3R dans la recherche préclinique
Utiliser les données actuelles et futures
Reconnaître les méthodes de substitution est une chose, mais quelles sont les possibilités potentielles des mégadonnées de faire avancer les 3R? Les mégadonnées renferment un potentiel encore en friche, susceptible d’accélérer et d’améliorer la recherche biomédicale. Mais comment cela peut-il fonctionner? Les résultats de la recherche sont publiés dans des revues scientifiques spécialisées, ainsi aussi les résultats de l’expérimentation animale. Cependant, les données issues des essais, par exemple les informations sur la méthode employée, les résultats concernant la dose à partir de laquelle un médicament a causé des effets secondaires ou a été efficace contre une maladie, ne sont disponibles nulle part sous une forme permettant aux scientifiques d’utiliser et de comparer les résultats d’études précédentes. Pour pouvoir tirer des enseignements d’expériences déjà réalisées sur des animaux, il faudrait que les données disponibles sur ces expériences, indépendamment du fait que les résultats aient été positifs ou négatifs, soient par exemple rassemblées et interconnectées sur une plateforme numérique de manière à ce que les chercheuses et chercheurs y aient accès facilement et rapidement. Un exemple: les comprimés se composent d’une substance active qui agit contre une maladie et d’excipients, des substances qui permettent de former et d’agglomérer le comprimé. Ces excipients ne doivent déclencher aucun effet toxique et doivent donc aussi être testés dans des expériences sur animaux. Comme on emploie largement les excipients dans la fabrication de comprimés, il serait utile de regrouper tous les tests toxicologiques dans une banque de données, de sorte que d’autres scientifiques des universités ou de l’industrie pharmaceutique puissent accéder aux résultats et s’en servir pour leurs propres applications, sans avoir à refaire les mêmes tests. On voit donc que les mégadonnées ne fournissent un bénéfice notable que si elles sont interconnectées et accessibles. Rendre ces données existantes utilisables par la collectivité signifie aussi mettre en route une évolution des mentalités et surmonter les silos qui existent au sein des institutions et entre les différentes institutions de recherche et entreprises.
L’utilisation de l’intelligence artificielle requiert de grands ensembles de données

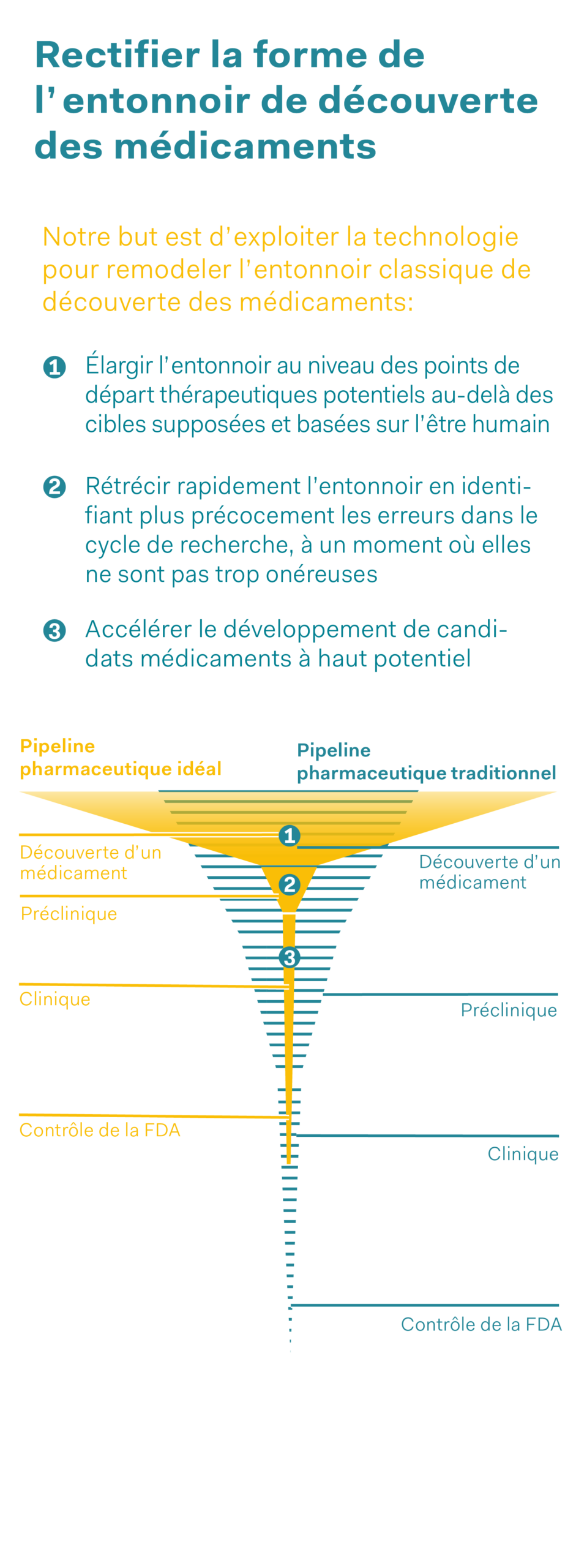
Dès lors que de grandes quantités de données sont disponibles, la question de l’utilisation de l’intelligence artificielle (IA) se pose. En effet, l’interconnexion de données issues de l’expérimentation animale pourrait non seulement éviter de répéter les expériences, mais aussi permettre le développement de techniques et applications entièrement nouvelles. On pourrait par exemple utiliser l’intelligence artificielle pour modéliser des expériences sur animaux et prédire ainsi l’efficacité et la sécurité d’un médicament sans avoir à faire des essais sur l’animal. La majeure partie du développement traditionnel de médicaments (nombre de tests sur de potentielles substances actives candidates) se compose des phases «découverte» de nouvelles substances actives et «tests in vitro», par exemple en cultures cellulaires, de ces nouvelles substances. L’étape suivante consiste à tester un médicament potentiel chez l’animal avant de faire des essais cliniques chez l’être humain. L’intelligence artificielle pourrait considérablement contribuer à étendre la recherche in vitro et à éviter certaines expériences sur animaux à la phase préclinique, donc à en réduire encore le nombre. Elle renferme aussi le potentiel d’accélérer le processus de développement de médicaments, de l’idée à l’autorisation de mise sur le marché, et de découvrir des erreurs à un stade plus précoce du développement, de sorte que seules les substances candidates très prometteuses parviendraient à la phase clinique. Mais l’utilisation de l’intelligence artificielle requiert de grandes quantités de données et l’accès aux ensembles de données, sans oublier de veiller à la protection de la propriété intellectuelle. En outre, elle requiert surtout des scientifiques capables de l’utiliser de manière pertinente, d’évaluer les résultats obtenus et de prendre des décisions sur cette base.